Остальные статьи цикла:
- Часть 1. Профилирование и настройки Django
- Часть 2. Работа с базой данных
- Часть 3. Кэширование
Django это мощный фреймворк используемый в множестве отличных проектов. Из коробки в нем включено много полезных батареек, которые значительно ускоряют разработку и соответственно уменьшают ее стоимость. Однако, когда проект растет и набирает аудиторию, вы неизбежно столкнетесь с проблемами производительности. В этом посте я попробую рассказать о том с какими проблемами вы можете столкнуться и как их решить.
Это первая статья из серии, здесь будут рассмотрено профилирование и настройки Django.
Профилирование
Перед тем выполнять оптимизацию необходимо измерить текущую производительность, чтобы после оптимизации можно было сравнить результаты. Такие измерения нужно будет делать часто, после каждого изменения, так что процесс должен быть автоматизированным.
Профилирование - это процесс измерения метрик проекта. Таких как: время ответа сервера, использование CPU, использование памяти и тд. Python предоставляет профайлер в стандартной библиотеке, который вполне удобно использовать для измерения производительности кусков кода. Но для профилирования целового проекта существуют более удобные решения.
Логирование
Самая частая проблема производительности это лишние и/или не эффективные запросы к БД. Можно настроить логирование,
для просмотра всех SQL запросов, которые выполняются в процессе обработки запроса. Добавьте в settings.py:
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console': {
'class': 'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'level': 'DEBUG',
'handlers': ['console'],
}
},
}
Убедитесь, что DEBUG = True и перезагрузите сервер. Теперь в консоли должны выводится все SQL запросы и длительность
выполнения каждого из них.
(0.002) SELECT DISTINCT "handbooks_size"."size_type_id", "goods_goods"."size_id" FROM "goods_goods" LEFT OUTER JOIN "handbooks_size" ON ("goods_goods"."size_id" = "handbooks_size"."id") WHERE "goods_goods"."status" IN ('reserved', 'sold', 'approved') ORDER BY "goods_goods"."size_id" ASC; args=('reserved', 'sold', 'approved')
(0.001) SELECT DISTINCT "goods_goods"."color_id" FROM "goods_goods" WHERE "goods_goods"."status" IN ('reserved', 'sold', 'approved') ORDER BY "goods_goods"."color_id" ASC; args=('reserved', 'sold', 'approved')
(0.001) SELECT DISTINCT "handbooks_size"."row", "handbooks_size"."size_type_id", "goods_goods"."size_id" FROM "goods_goods" LEFT OUTER JOIN "handbooks_size" ON ("goods_goods"."size_id" = "handbooks_size"."id") WHERE "goods_goods"."status" IN ('reserved', 'sold', 'approved') ORDER BY "goods_goods"."size_id" ASC; args=('reserved', 'sold', 'approved')
(0.000) SELECT DISTINCT "goods_goods"."season" FROM "goods_goods" WHERE "goods_goods"."status" IN ('reserved', 'sold', 'approved') ORDER BY "goods_goods"."season" ASC; args=('reserved', 'sold', 'approved')
(0.000) SELECT DISTINCT "goods_goods"."state" FROM "goods_goods" WHERE "goods_goods"."status" IN ('reserved', 'sold', 'approved') ORDER BY "goods_goods"."state" ASC; args=('reserved', 'sold', 'approved')
(0.002) SELECT MAX("__col1"), MIN("__col2") FROM (SELECT "goods_goods"."id" AS Col1, CASE WHEN "goods_goods"."status" = 'sold' THEN 1 ELSE 0 END AS "x_order", "goods_goods"."price_sell" AS "__col1", "goods_goods"."price_sell" AS "__col2" FROM "goods_goods" WHERE "goods_goods"."status" IN ('reserved', 'sold', 'approved') GROUP BY "goods_goods"."id", CASE WHEN "goods_goods"."status" = 'sold' THEN 1 ELSE 0 END) subquery; args=('sold', 1, 0, 'reserved', 'sold', 'approved', 'sold', 1, 0)
(0.001) SELECT COUNT(*) FROM (SELECT "goods_goods"."id" AS Col1, CASE WHEN "goods_goods"."status" = 'sold' THEN 1 ELSE 0 END AS "x_order" FROM "goods_goods" WHERE "goods_goods"."status" IN ('reserved', 'sold', 'approved') GROUP BY "goods_goods"."id", CASE WHEN "goods_goods"."status" = 'sold' THEN 1 ELSE 0 END) subquery; args=('sold', 1, 0, 'reserved', 'sold', 'approved', 'sold', 1, 0)
[15/Jun/2017 11:03:49] "GET /goods HTTP/1.0" 200 32583
Django Debug Toolbar
Это Django приложение, которые предоставляет набор панелей,
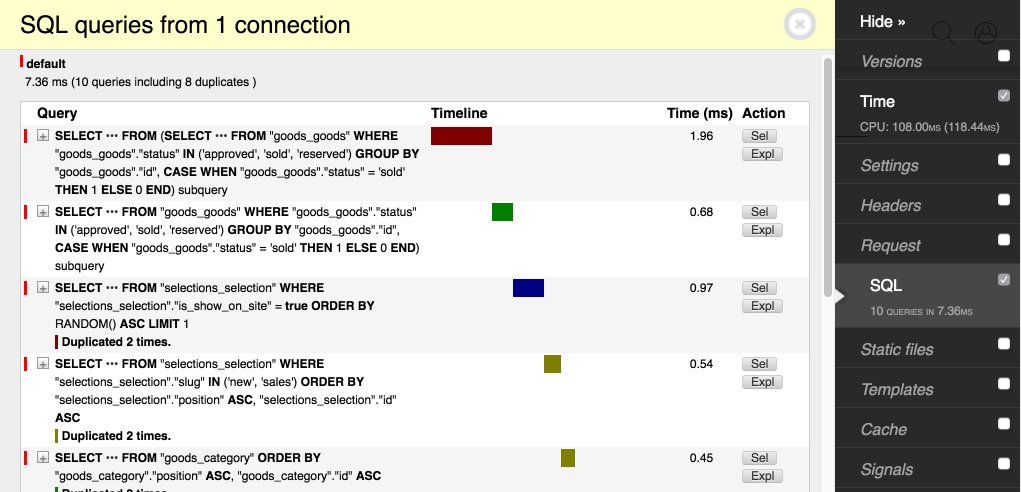
некоторые из которых удобно использовать для профилирование. По умолчанию включена SQL панель, которая предоставляет
даже больше информации чем стандартное логирование Django. Некоторые дополнительные возможности: временная диаграмма
запросов, traceback, просмотр результатов и EXPLAIN каждого запроса.
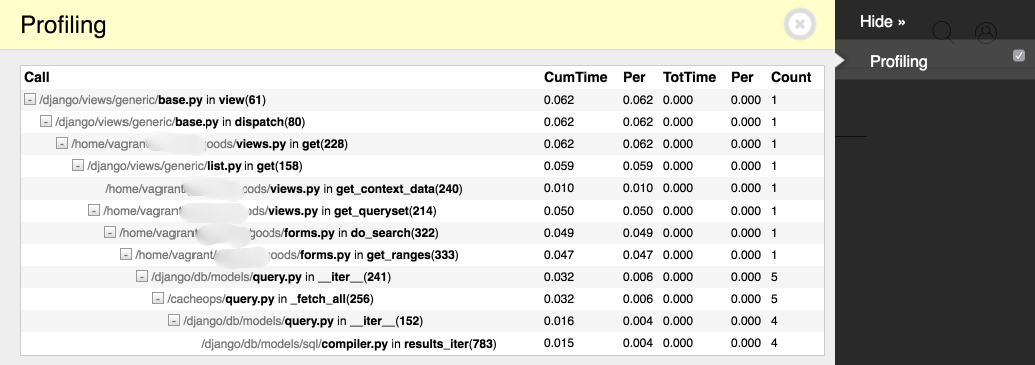
DDT также поставляется с отключенной по умолчанию панелью для профилирования. Эта панель отображает результаты профилирования
в удобном web-интерфейсе. Для включения панели добавьте debug_toolbar.panels.profiling.ProfilingPanel в
список DEBUG_TOOLBAR_PANELS в settings.py.
Silk
Еще один отличный пакет, который особенно пригодится если у вас API и соответственно DDT нельзя использовать. Как установить и настроить пакет можно посмотреть на github проекта.
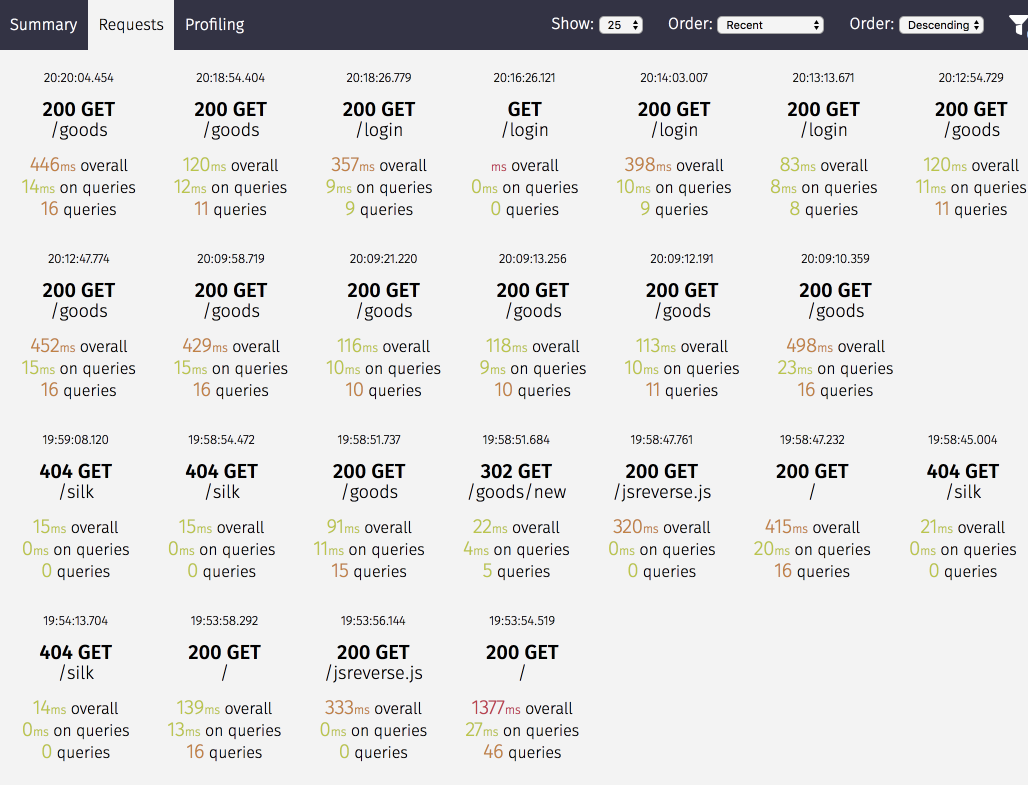
После установки и настройки перезагрузите сервер и перейдите по URL: /silk/. По этому адресу должен быть доступен
web-интерфейс, который показывает:
- Статистику по запросам (в разрезе метод/URL с возможностью просмотра отдельных запросов),
- просмотр SQL запросов,
- просмотр результатов профилирования.
Профайлер можно включить для всего проекта установив SILKY_PYTHON_PROFILER = True в settings.py. Или использовать
только в определенных местах, заключив профилируемый код в декоратор или контекст процессор:
from silk.profiling.profiler import silk_profile
@silk_profile(name='View Blog Post')
def post(request, post_id):
p = Post.objects.get(pk=post_id)
return render_to_response('post.html', {
'post': p
})
def post(request, post_id):
with silk_profile(name='View Blog Post #%d' % self.pk):
p = Post.objects.get(pk=post_id)
return render_to_response('post.html', {
'post': p
})
Тестовые данные
Очень важно использовать для профилирования данные похожие на те, что используются в production. В идеале нужно взять бекап с production сервера, развернуть его на локальной машине и использовать эти данные для профилирования проекта. Если вы попробуете профилировать проект на пустой/маленькой базе данных, вероятно, вы получите некорректный результат, который не будет соответствовать реальным проблемам на боевом окружении, что не поможет выполнить нужные оптимизации.
Нагрузочное тестирование
После оптимизации хорошей идеей будет провести нагрузочное тестирование, чтобы убедится, что уровень производительности приложения соответствует реальной (или ожидаемой) нагрузке или SLA. Для этого типа тестирования вам потребуется окружение аналогичное используемому на production. К счастью облачные сервисы и автоматизированная сборка проектов позволяют разворачивать такое окружение за считанные минуты.
Рекомендую использовать Locust для нагрузочного тестирования. Главное преимущество Locust,
что тесты описываются в виде Python кода. Можно настраивать сложные сценарии тестирования, чтобы максимально
приблизить нагрузку к той, которую генерируют реальные пользователи. Пример locustfile.py:
from locust import HttpLocust, TaskSet, task
class UserBehavior(TaskSet):
def on_start(self):
""" on_start is called when a Locust start before any task is scheduled """
self.login()
def login(self):
self.client.post("/login", {"username":"ellen_key", "password":"education"})
@task(2)
def index(self):
self.client.get("/")
@task(1)
def profile(self):
self.client.get("/profile")
class WebsiteUser(HttpLocust):
task_set = UserBehavior
min_wait = 5000
max_wait = 9000
Также Locust предоставляет web-интерфейс для запуска тестов и просмотра результатов:
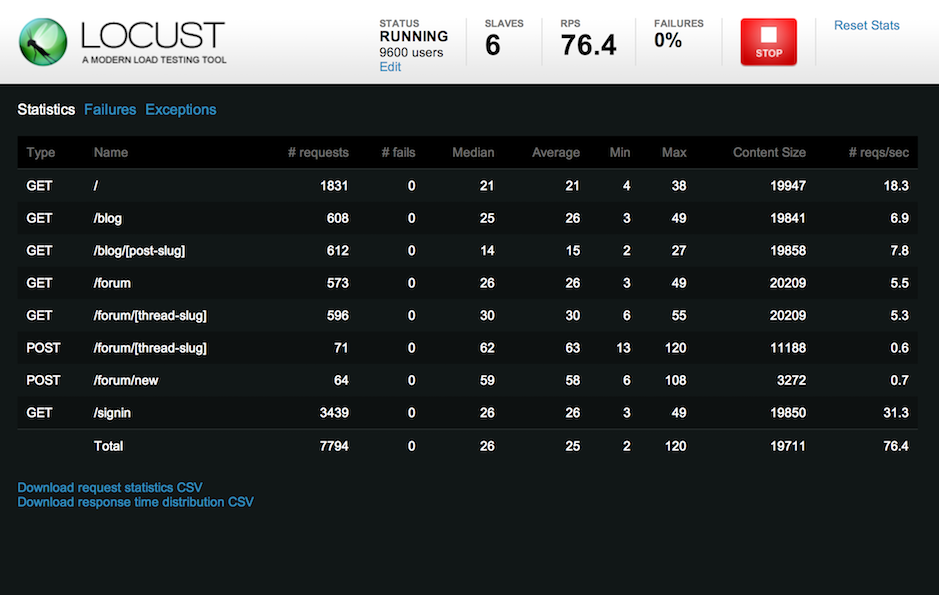
Лучше всего то, что можно настроить Locust один раз и использовать для тестирования производительности после каждого вносимого изменения. Возможно вы даже сможете добавить его в ваш CI/CD pipeline.
Настройки Django
В этом разделе мы рассмотрим настройки Django, которые могут повлиять на производительность.
TTL соединения с БД
По умолчанию Django закрывает соединение с БД после завершения каждого запроса. Можно настроить TTL соединения с БД,
изменив значение параметра CONN_MAX_AGE:
0- закрывать соединение после выполнения каждого запроса> 0- TTL в секундах,None- неограниченное TTL.
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql',
'NAME': 'mydatabase',
'USER': 'mydatabaseuser',
'PASSWORD': 'mypassword',
'HOST': '127.0.0.1',
'PORT': '5432',
'CONN_MAX_AGE': 60 * 10, # 10 minutes
}
}
Кэширование шаблонов
Если вам приходится использовать Django версии меньше чем 1.11, то вы можете рассмотреть включение кэширования шаблонов.
По умолчанию, Django (<1.11) считывает и компилирует шаблоны каждый раз, когда они рендерятся. Можно использовать
загрузчик django.template.loaders.cached.Loader для включения кэширования шаблонов в памяти. Отредактируйте в
settings.py:
TEMPLATES = [
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
'DIRS': [os.path.join(BASE_DIR, 'foo', 'bar'), ],
'OPTIONS': {
# ...
'loaders': [
('django.template.loaders.cached.Loader', [
'django.template.loaders.filesystem.Loader',
'django.template.loaders.app_directories.Loader',
]),
],
},
},
]
Redis как хранилище кэша
Django предоставляет несколько вариантов хранилищ для кэша, например, БД, файловая система и тд. Рекомендую хранить кэш
в Redis - популярное хранилище объектов в памяти, с большой вероятностью вы уже используете его в своем проекте.
Для настройки Redis, как хранилища кэша нам нужно будет установить сторонний пакет, например django-redis.
Устанавливаем django-redis при помощи pip:
pip install django-redis
Добавьте настройки кэша в settings.py:
CACHES = {
"default": {
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": "redis://127.0.0.1:6379/1",
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient",
}
}
}
Читайте полную документацию здесь.
Хранилище сессий
По умолчанию Django хранит сессии в БД. Для ускорения не помешает хранить сессии в кэше. Добавьте следующее
в settings.py:
SESSION_ENGINE = "django.contrib.sessions.backends.cache"
SESSION_CACHE_ALIAS = "default"
Удаление ненужных middleware
Проверьте список используемых middleware (MIDDLEWARE в settings.py). Убедитесь, что там нет ничего не нужного.
Django вызывает каждый middleware для каждого обрабатываемого запроса, так что накладные расходы могут быть значительными.
Если у вас есть какой-либо кастомный middleware, который используется не для всех запросов, попробуйте вынести его функциональность в mixin для view или декоратор. Это позволит избавится от задержек при обработке остальных запросов, которые не требуют такой функциональности.