Остальные статьи цикла:
- Часть 1. Профилирование и настройки Django
- Часть 2. Работа с базой данных
- Часть 3. Кэширование
Содержание:
- Массовые изменения
- Iterator
- Использование внешних ключей
- Получение связанных объектов
- Ограничение полей в выборках
- Индексы БД
- len(qs) vs qs.count
- count vs exists
- Ленивый QuerySet
Это продолжение серии статей про оптимизацию Django приложений. Первая часть доступна здесь и рассказывает о профилировании и настройках Django. В этой части мы рассмотрим оптимизацию работы с БД (модели Django).
В этой части часто будет использоваться логирование SQL запросов и DDT, про которые написано в первом посте. В качестве БД во всех примерах будет использоваться PostgreSQL, но для пользователей других СУБД большая часть статьи также будет актуальна.
Примеры в этой части будут основаны на простом приложении блога, которое мы будем разрабатывать и оптимизировать по ходу статьи. Начнем с следующих моделей:
from django.db import models
class Tag(models.Model):
name = models.CharField(max_length=64)
def __str__(self):
return self.name
class Author(models.Model):
username = models.CharField(max_length=64)
email = models.EmailField()
bio = models.TextField()
def __str__(self):
return self.username
class Article(models.Model):
title = models.CharField(max_length=64)
content = models.TextField()
created_at = models.DateField()
author = models.ForeignKey(Author)
tags = models.ManyToManyField(Tag)
def __str__(self):
return self.title
Весь код доступен на GitHub с разбивкой по тегам.
Массовые изменения
Массовая вставка
Предположим, что наше новое приложение блога заменяет старое приложение и нам нужно перенести данные в новые модели. Мы экспортировали данные из старого приложения в огромные JSON файлы. Файл с авторами имеет следующий вид:
[
{
"username": "mackchristopher",
"email": "dcortez@yahoo.com",
"bio": "Vitae mollitia in modi suscipit similique. Tempore sunt aliquid porro. Molestias tempora quos corporis quam."
}
]
Сделаем команду Django для импортирования авторов из JSON файла:
class Command(BaseCommand):
help = 'Load authors from `data/old_authors.json`'
DATA_FILE_PATH = os.path.join(settings.BASE_DIR, '..', 'data', 'old_data.json')
def handle(self, *args, **kwargs):
with open(self.DATA_FILE_PATH, 'r') as json_file:
data = json.loads(json_file.read())
for author in data:
self._import_author(author)
def _import_author(self, author_data):
author = Author(
username=author_data['username'],
email=author_data['email'],
bio=author_data['bio'])
author.save()
Проверим сколько SQL запросов выполняется при загрузке 200 авторов. Используем python manage.py shell:
from django.core.management import call_command
from django.db import connection
call_command('load_data')
print(len(connection.queries))
Этот код выведет множество SQL запросов (т.к. у нас включено их логирование), а в последней строке будет число 200.
Это означает, что для каждого автора выполняется отдельный INSERT SQL запрос. Если у вас большое количество данных,
то такой подход может быть очень медленным. Воспользуемся методом bulk_create менеджера модели Author:
def handle(self, *args, **kwargs):
with open(self.DATA_FILE_PATH, 'r') as json_file:
data = json.loads(json_file.read())
author_instances = []
for author in data:
author_instances.append(self._import_author(author))
Author.objects.bulk_create(author_instances)
def _import_author(self, author_data):
author = Author(
username=author_data['username'],
email=author_data['email'],
bio=author_data['bio'])
return author
Запустив команду, описанным выше способом, мы увидим, что был выполнен один огромный запрос к БД, для всех авторов.
Если вам действительно нужно вставить большой объем данных, возможно, придется разбить вставку на несколько запросов. Для этого существует параметр
batch_sizeу методаbulk_create, который задает максимальное количество объектов, которые будут вставлены за один запрос. Т.е. если у нас 200 объектов, задавbulk_size = 50мы получим 4 запроса.У метода
bulk_sizeесть ряд ограничений с которыми вы можете ознакомиться в документации.
Массовая вставка M2M
Теперь нам нужно вставить статьи и теги, которые находятся в отдельном JSON файле с следующей структурой:
[
{
"created_at": "2016-06-11",
"author": "nichole52",
"tags": [
"ab",
"iure",
"iusto"
],
"title": "...",
"content": "..."
}
]
Напишем для этого еще одну команду Django:
class Command(BaseCommand):
help = 'Load articles from `data/old_articles.json`'
DATA_FILE_PATH = os.path.join(settings.BASE_DIR, '..', 'data', 'old_articles.json')
def handle(self, *args, **kwargs):
with open(self.DATA_FILE_PATH, 'r') as json_file:
data = json.loads(json_file.read())
for article in data:
self._import_article(article)
def _import_article(self, article_data):
author = Author.objects.get(username=article_data['author'])
article = Article(
title=article_data['title'],
content=article_data['content'],
created_at=article_data['created_at'],
author=author)
article.save()
for tag in article_data['tags']:
tag_instance, _ = Tag.objects.get_or_create(name=tag)
article.tags.add(tag_instance)
Запустив ее я получил 3349 SQL запросов! Многие из которых имели следующий вид:
(0.001) SELECT "blog_article_tags"."tag_id" FROM "blog_article_tags" WHERE ("blog_article_tags"."article_id" = 2319 AND "blog_article_tags"."tag_id" IN (67)); args=(2319, 67)
(0.000) INSERT INTO "blog_article_tags" ("article_id", "tag_id") VALUES (2319, 67) RETURNING "blog_article_tags"."id"; args=(2319, 67)
(0.000) SELECT "blog_tag"."id", "blog_tag"."name" FROM "blog_tag" WHERE "blog_tag"."name" = 'fugiat'; args=('fugiat',)
(0.001) SELECT "blog_article_tags"."tag_id" FROM "blog_article_tags" WHERE ("blog_article_tags"."article_id" = 2319 AND "blog_article_tags"."tag_id" IN (68)); args=(2319, 68)
(0.000) INSERT INTO "blog_article_tags" ("article_id", "tag_id") VALUES (2319, 68) RETURNING "blog_article_tags"."id"; args=(2319, 68)
(0.000) SELECT "blog_tag"."id", "blog_tag"."name" FROM "blog_tag" WHERE "blog_tag"."name" = 'repellat'; args=('repellat',)
(0.001) SELECT "blog_article_tags"."tag_id" FROM "blog_article_tags" WHERE ("blog_article_tags"."article_id" = 2319 AND "blog_article_tags"."tag_id" IN (58)); args=(2319, 58)
(0.000) INSERT INTO "blog_article_tags" ("article_id", "tag_id") VALUES (2319, 58) RETURNING "blog_article_tags"."id"; args=(2319, 58
Добавление каждого тега к статье выполняется отдельным запросом. Это можно улучшить передавая методу article.tags.add
сразу список тегов:
def _import_article(self, article_data):
# ...
tags = []
for tag in article_data['tags']:
tag_instance, _ = Tag.objects.get_or_create(name=tag)
tags.append(tag_instance)
article.tags.add(*tags)
Этот вариант отправляет 1834 запроса, почти в 2 раза меньше, неплохой результат, учитывая что мы изменили всего лишь пару строк кода.
Массовое изменение
После переноса данных пришла идея, что к старым статьям (раньше 2012 года) нужно запретить комментирование. Для этого
было добавлено логическое поле comments_on к модели Article и нам необходимо проставить его значение:
from django.db import connection
from blog.models import Article
for article in Article.objects.filter(created_at__year__lt=2012):
article.comments_on = False
article.save()
print(len(connection.queries))
Запустив этот код я получил 179 запросов следующего вида:
(0.000) UPDATE "blog_article" SET "title" = 'Saepe eius facere magni et eligendi minima sint.', "content" = '...', "created_at" = '1992-03-01'::date, "author_id" = 730, "comments_on" = false WHERE "blog_article"."id" = 3507; args=('Saepe eius facere magni et eligendi minima sint.', '...', datetime.date(1992, 3, 1), 730, False, 3507)
Кроме того, что для каждой статьи подходящей по условию происходит отдельный SQL запрос, еще и все поля этих статей
перезаписываются. А это может привести к перезаписи изменений сделанных в промежутке между SELECT и UPDATE запросами.
Т.е. кроме проблем с производительностью мы также получаем race condition.
Вместо этого мы можем использовать метод update доступный у объектов QuerySet:
Article.objects.filter(created_at__year__lt=2012).update(comments_on=False)
Этот код генерирует всего один SQL запрос:
(0.004) UPDATE "blog_article" SET "comments_on" = false WHERE "blog_article"."created_at" < '2012-01-01'::date; args=(False, datetime.date(2012, 1, 1))
Если для изменения полей нужна сложная логика, которую нельзя реализовать полностью в update операторе, можете вычислить значение поля в Python коде и затем использовать один из следующих вариантов:
Model.object.filter(id=instance.id).update(field=computed_value)
# or
instance.field = computed_value
instance.save(update_fields=('fields',))
Но оба эти варианта также страдают от race condition, хоть и в меньшей степени.
Массовое удаление объектов
Сейчас нам потребовалось удалить все статьи отмеченные тегом minus:
from django.db import connection
from blog.models import Article
for article in Article.objects.filter(tags__name='minus'):
article.delete()
print(len(connection.queries))
Код сгенерировал 93 запроса следующего вида:
(0.000) DELETE FROM "blog_article_tags" WHERE "blog_article_tags"."article_id" IN (3510); args=(3510,)
(0.000) DELETE FROM "blog_article" WHERE "blog_article"."id" IN (3510); args=(3510,)
Сначала удаляется связь статьи с тегом в промежуточной таблице, а затем и сама статья. Мы можем сделать это за
меньшее количество запросов, используя метод delete класса QuerySet:
from django.db import connection
from blog.models import Article
Article.objects.filter(tags__name='minus').delete()
print(len(connection.queries))
Этот код выполняет то же самое всего за 3 запроса к БД:
(0.004) SELECT "blog_article"."id", "blog_article"."title", "blog_article"."content", "blog_article"."created_at", "blog_article"."author_id", "blog_article"."comments_on" FROM "blog_article" INNER JOIN "blog_article_tags" ON ("blog_article"."id" = "blog_article_tags"."article_id") INNER JOIN "blog_tag" ON ("blog_article_tags"."tag_id" = "blog_tag"."id") WHERE "blog_tag"."name" = 'minus'; args=('minus',)
(0.002) DELETE FROM "blog_article_tags" WHERE "blog_article_tags"."article_id" IN (3713, 3717, 3722, ...); args=(3713, 3717, 3722, ...)
(0.001) DELETE FROM "blog_article" WHERE "blog_article"."id" IN (3713, 3717, ...); args=(3713, 3717, 3722, ...)``sql
Сначала одним запросом получается список идентификаторов всех статей, отмеченных тегом minus, затем второй запрос
удаляет связи сразу всех этих статей с тегами, и последний запрос удаляет статьи.
Iterator
Предположим, нам нужно добавить возможность экспорта статей в CSV формат. Сделаем для этого простую команду Django:
class Command(BaseCommand):
help = 'Export articles to csv'
EXPORT_FILE_PATH = os.path.join(settings.BASE_DIR, '..', 'data', 'articles_export.csv')
COLUMNS = ['title', 'content', 'created_at', 'author', 'comments_on']
def handle(self, *args, **kwargs):
with open(self.EXPORT_FILE_PATH, 'w') as export_file:
articles_writer = csv.writer(export_file, delimiter=';')
articles_writer.writerow(self.COLUMNS)
for article in Article.objects.select_related('author').all():
articles_writer.writerow([getattr(article, column) for column in self.COLUMNS])
Для тестирования этой команды я сгенерировал около 100Мb статей и загрузил их в БД. Далее я запустил команду через профайлер памяти memory_profiler.
mprof run python manage.py export_articles
mprof plot
В результате я получил следующий график по использованию памяти:
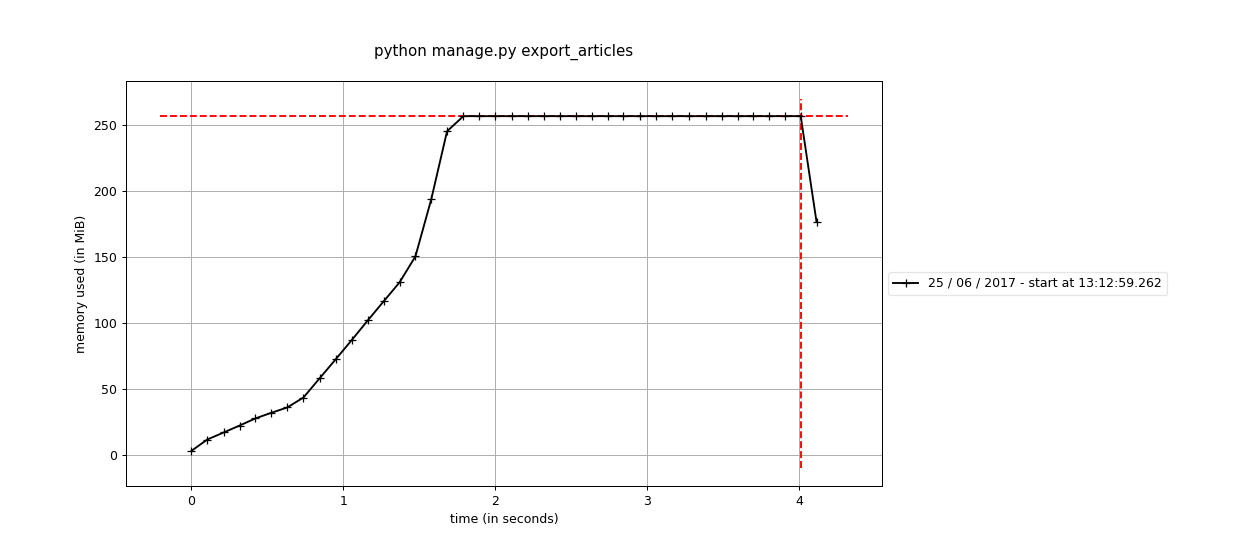
Команда использует около 250Mb памяти, потому что при выполнении запроса QuerySet получает из БД сразу все статьи и
кэширует их в памяти, чтобы при последующем обращении к этому QuerySet дополнительные запросы не выполнялись.
Мы можем уменьшить объем используемой памяти, используя метод iterator класса QuerySet, который позволяет получать
результаты по одному, используя server-side cursor, и при этом он отключает
кэширование результатов в QuerySet:
# ...
for article in Article.objects.select_related('author').iterator():
# ...
Запустив обновленный пример в профайлере я получил следующий результат:
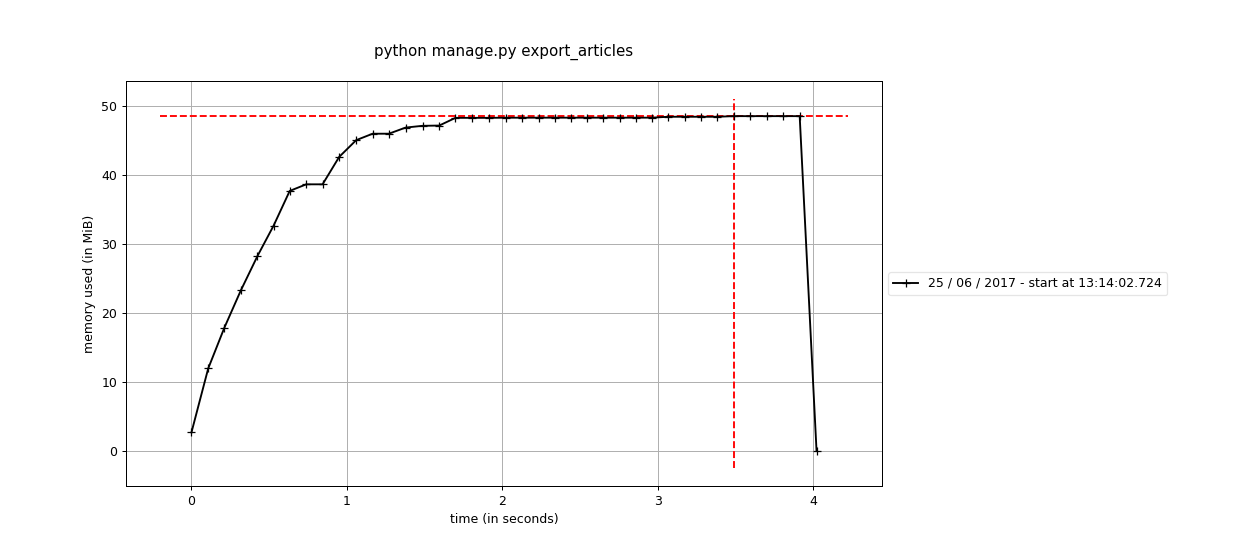
Теперь команда использует всего 50Mb. Также приятным побочным эффектом является то, что при любом размере данных,
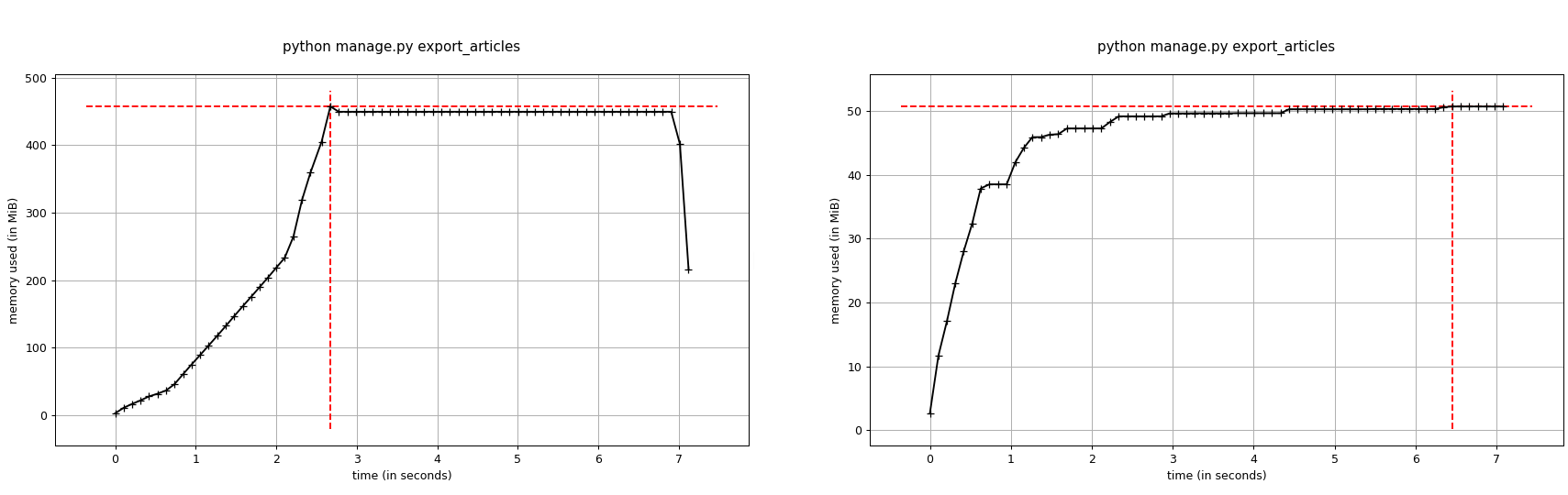
при использовании iterator, команда использует постоянный объем памяти. Вот графики для ~200Mb статей
(без iterator и с ним соответственно):
Использование внешних ключей
Теперь нам потребовалось добавить действие в админку статей для создания копии статьи:
def clone_article(modeladmin, request, queryset):
if queryset.count() != 1:
modeladmin.message_user(request, "You could clone only one article at a time.", level=messages.ERROR)
return
origin_article = queryset.first()
cloned_article = Article(
title="{} (COPY)".format(origin_article.title),
content=origin_article.content,
created_at=origin_article.created_at,
author=origin_article.author,
comments_on=origin_article.comments_on)
cloned_article.save()
cloned_article.tags = origin_article.tags.all()
modeladmin.message_user(request, "Article successfully cloned", level=messages.SUCCESS)
clone_article.short_description = 'Clone article'
В логах можно увидеть следующие запросы к БД:
(0.001) SELECT COUNT(*) AS "__count" FROM "blog_article" WHERE "blog_article"."id" IN (31582); args=(31582,)
(0.001) SELECT "blog_article"."id", "blog_article"."title", "blog_article"."content", "blog_article"."created_at", "blog_article"."author_id", "blog_article"."comments_on" FROM "blog_article" WHERE "blog_article"."id" IN (31582) ORDER BY "blog_article"."created_at" DESC, "blog_article"."id" DESC LIMIT 1; args=(31582,)
(0.000) SELECT "blog_author"."id", "blog_author"."username", "blog_author"."email", "blog_author"."bio" FROM "blog_author" WHERE "blog_author"."id" = 2156; args=(2156,)
(0.001) INSERT INTO "blog_article" ("title", "content", "created_at", "author_id", "comments_on") VALUES ('Explicabo maiores nobis cum vel fugit. (COPY)', ...
У нас почему-то запрашивается автор, хотя нам не нужны какие-либо данные об авторе, кроме его ID. Чтобы исправить это,
нужно обращаться к внешнему ключу напрямую, для получения id автора нужно использовать origin_article.author_id.
Теперь код клонирования статьи будет выглядеть следующим образом:
cloned_article = Article(
title="{} (COPY)".format(origin_article.title),
content=origin_article.content,
created_at=origin_article.created_at,
author_id=origin_article.author_id,
comments_on=origin_article.comments_on)
И в логах больше нет запросов на получение информации об авторе.
Получение связанных объектов
Наконец-то пришло время сделать наши статьи публично доступными, и начнем мы со страницы со списком статей. Реализуем
view, используя ListView:
class ArticlesListView(ListView):
template_name = 'blog/articles_list.html'
model = Article
context_object_name = 'articles'
paginate_by = 20
В шаблоне мы выводим информацию о статье, авторе и тегах:
<article>
<h2>{{ article.title }}</h2>
<time>{{ article.created_at }}</time>
<p>Author: {{ article.author.username }}</p>
<p>Tags:
{% for tag in article.tags.all %}
{{ tag }}{% if not forloop.last %}, {% endif %}
{% endfor %}
</article>
DDT показывает при открытии списка статей 45 SQL запросов следующего вида:
(0.002) SELECT "blog_article"."id", "blog_article"."title", "blog_article"."content", "blog_article"."created_at", "blog_article"."author_id", "blog_article"."comments_on" FROM "blog_article" LIMIT 20; args=()
(0.001) SELECT "blog_author"."id", "blog_author"."username", "blog_author"."email", "blog_author"."bio" FROM "blog_author" WHERE "blog_author"."id" = 2043; args=(2043,)
(0.001) SELECT "blog_tag"."id", "blog_tag"."name" FROM "blog_tag" INNER JOIN "blog_article_tags" ON ("blog_tag"."id" = "blog_article_tags"."tag_id") WHERE "blog_article_tags"."article_id" = 20425; args=(20425,)
(0.000) SELECT "blog_author"."id", "blog_author"."username", "blog_author"."email", "blog_author"."bio" FROM "blog_author" WHERE "blog_author"."id" = 2043; args=(2043,)
(0.001) SELECT "blog_tag"."id", "blog_tag"."name" FROM "blog_tag" INNER JOIN "blog_article_tags" ON ("blog_tag"."id" = "blog_article_tags"."tag_id") WHERE "blog_article_tags"."article_id" = 20426; args=(20426,)
Т.е. мы сначала получаем все статьи одним SQL запросом (с учетом пагинации) и затем для каждой из этих статей отдельно запрашиваются автор и теги. Нам нужно заставить Django запросить все эти данные меньшим количеством запросов.
Начнем с получения авторов, для того, чтобы QuerySet получил заранее данные по определенным внешним ключам есть метод select_related. Обновим queryset в нашем view для использования этого метода:
queryset = Article.objects.select_related('author')
После этого DDT показывает уже 25 SQL запросов, т.к. получение информации об авторах и статьях теперь выполняется одним
SQL запросом с JOIN:
(0.004) SELECT "blog_article"."id", "blog_article"."title", "blog_article"."content", "blog_article"."created_at", "blog_article"."author_id", "blog_article"."comments_on", "blog_author"."id", "blog_author"."username", "blog_author"."email", "blog_author"."bio" FROM "blog_article" INNER JOIN "blog_author" ON ("blog_article"."author_id" = "blog_author"."id") LIMIT 21; args=()
Метод select_related работает только с внешними ключами в текущей модели, для того, чтобы уменьшить количество запросов
при получении множества связанных объектов (таких как теги в нашем примере), нужно использовать метод prefetch_related.
Опять обновим атрибут queryset у класса AticlsListView:
queryset = Article.objects.select_related('author').prefetch_related('tags')
И теперь DDT показывает всего 7 запросов. Если проигнорировать запросы, которые выполняет пагинатор и запросы, связанные с сессией получаем всего 2 запроса для отображения списка статей:
(0.002) SELECT "blog_article"."id", "blog_article"."title", "blog_article"."content", "blog_article"."created_at", "blog_article"."author_id", "blog_article"."comments_on", "blog_author"."id", "blog_author"."username", "blog_author"."email", "blog_author"."bio" FROM "blog_article" INNER JOIN "blog_author" ON ("blog_article"."author_id" = "blog_author"."id") LIMIT 20; args=()
(0.001) SELECT ("blog_article_tags"."article_id") AS "_prefetch_related_val_article_id", "blog_tag"."id", "blog_tag"."name" FROM "blog_tag" INNER JOIN "blog_article_tags" ON ("blog_tag"."id" = "blog_article_tags"."tag_id") WHERE "blog_article_tags"."article_id" IN (16352, 16353, 16354, 16355, 16356, 16357, 16358, 16359, 16360, 16361, 16362, 16363, 16344, 16345, 16346, 16347, 16348, 16349, 16350, 16351); args=(16352, 16353, 16354, 16355, 16356, 16357, 16358, 16359, 16360, 16361, 16362, 16363, 16344, 16345, 16346, 16347, 16348, 16349, 16350, 16351)
Используйте
select_relatedдля внешних ключей в текущей модели. Для получения M2M объектов и объектов из моделей ссылающихся на текущую, используйтеprefetch_related.Также
prefetch_relatedможно использовать для получения связанных объектов большей вложенности:
Tag.objects.all().prefetch_related('article_set__author')Этот код запросит вместе с тегом также все статьи отмеченные тегом и всех авторов этих статей.
Ограничение полей в выборках
Если мы присмотримся получше к SQL запросам в предыдущем примере, мы увидим, что мы получаем больше полей, чем нам нужно. В DDT можно посмотреть результаты запроса и убедиться в этом:
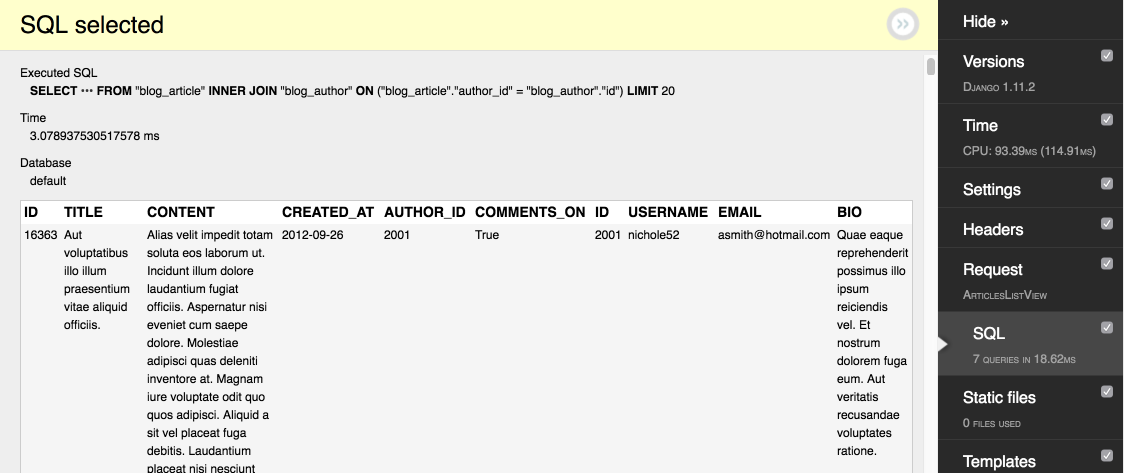
Мы получаем все поля автора и статьи, включая текст статьи огромного размера. Можно значительно
уменьшить объем передаваемых данных, используя метод defer, который позволяет отложить получение определенных полей.
В случае, если в коде все же произойдет обращение к такому полю, то Django сделает дополнительный запрос для его получения.
Добавим вызов метода defer в queryset:
queryset = Article.objects.select_related('author').prefetch_related('tags').defer('content', 'comments_on')
Теперь некоторые ненужные поля не запрашиваются и это уменьшило время обработки запроса, как нам показывает DDT
(до и после defer соответственно):

Мы все еще получаем множество полей автора, которые мы не используем. Проще было бы указать только те поля,
которые нам действительно нужны. Для этого есть метод only, передав которому названия полей, остальные поля будут отложены:
queryset = Article.objects.select_related('author').prefetch_related('tags').only(
'title', 'created_at', 'author__username', 'tags__name')
В результате мы получаем только нужные данные, что можно посмотреть в DDT:
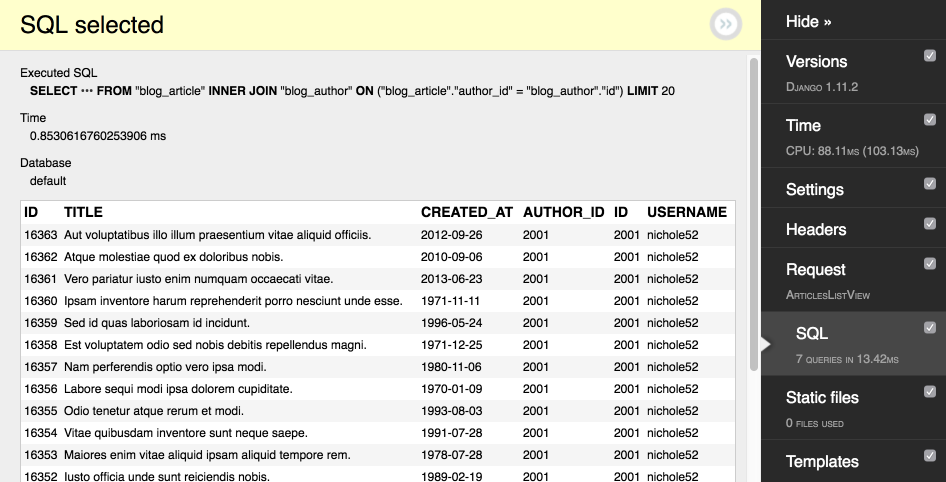
Т.е. defer и only выполняют одну и ту же задачу, ограничения полей в выборках, различие только в то что:
deferоткладывает получение полей переданных в качестве аргументов,onlyоткладывает получение всех полей, кроме переданных.
Индексы БД
Нам нужно сделать страницу автора, которая будет доступна по такому URL: /authors/<username>. Сделаем view
для этого:
def author_page_view(request, username):
author = get_object_or_404(Author, username=username)
return render(request, 'blog/author.html', context=dict(author=author))
Этот код работает достаточно быстро при небольшом объеме данных, но если объем значительный и продолжает расти, то
производительность будет только падать. Все дело в том, что для поиска по полю username СУБД приходится сканировать
всю таблицу до тех пор пока не найдет нужное значение. Есть вариант лучше - добавить на данное поле индекс, что позволит
СУБД искать гораздо эффективнее. Для добавления индекса нужно добавить аргумент db_index=True в объявление
поля username, а затем создать и применить миграции:
class Author(models.Model):
username = models.CharField(max_length=64, db_index=True)
# ...
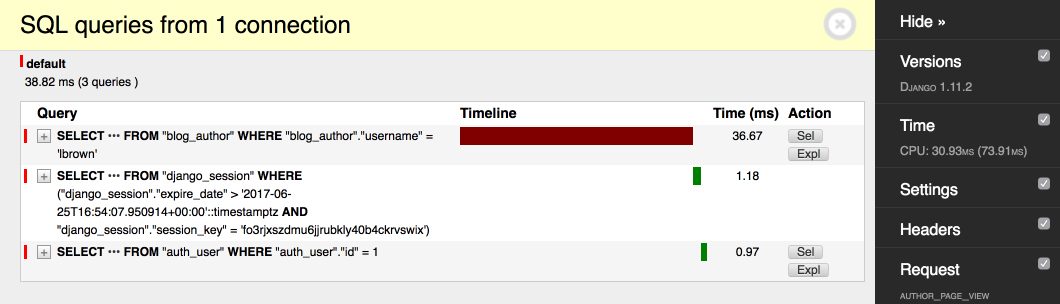
Сравним производительность до и после добавления индекса на БД авторов размером в 100К.
Без индекса:
С индексом:
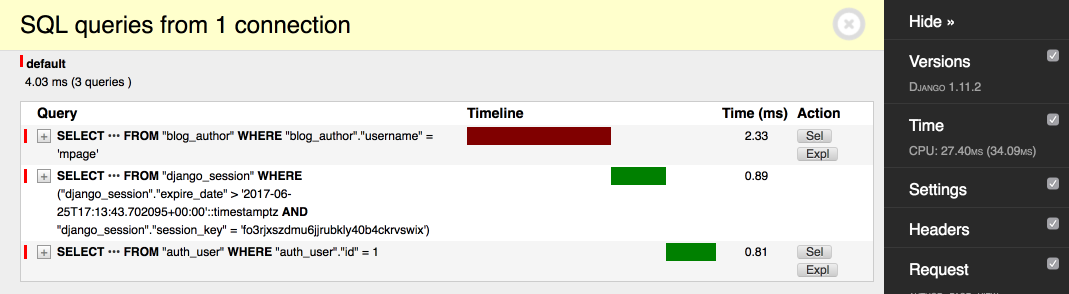
Запрос выполнился быстрее в 16 раз!
Индексы полезны не только при фильтрации данных, но и при сортировке. Также многие СУБД позволяют делать индексы по нескольким полям, что полезно, если вы фильтруете данные по набору полей. Советую изучить документацию к вашей СУБД, чтобы узнать подробности.
len(qs) vs qs.count
По какой-то причине, нам потребовалось вывести на странице со списком статей счетчик с количеством авторов. Обновим view:
class ArticlesListView(ListView):
# ...
def get_context_data(self, **kwargs):
context = super().get_context_data(**kwargs)
context['authors_count'] = len(Author.objects.all())
return context
Посмотрим какие SQL запросы генерирует этот код:

На скриншоте мы видим, что запрашиваются все значения из таблицы авторов, соответственно подсчет количества происходит
уже в самом view. Конечно это не самый оптимальный вариант и нам было бы достаточно получить из БД одно число -
количество авторов. Для этого можно использовать метод count:
context['authors_count'] = Author.objects.count()
Посмотрим результат в DDT:

Теперь Django сгенерировал намного более оптимальный запрос для нашей задачи.
count vs exists
На странице автора нужно вывести ссылку на каталог статей этого автора, если у него есть статьи. Одним из решений будет получить количество статей и сравнить равно ли количество 0, например так:
def author_page_view(request, username):
author = get_object_or_404(Author, username=username)
show_articles_link = (author.articles.count() > 0)
return render(
request, 'blog/author.html',
context=dict(author=author, show_articles_link=show_articles_link))
Но при большом количестве статей этот код будет работать медленно. Т.к. нам не нужно знать точное количество статей
у пользователя, то мы можем использовать метод exists, который проверяет, что в QuertSet есть хотя бы один результат:
# ...
show_articles_link = author.articles.exists()
# ...
Сравниваем производительность при большом количестве статей (~10K):

Мы достигли цели запросом, который выполняется в 10 раз быстрее.
Ленивый QuerySet
Теперь нам захотелось, чтобы авторы конкурировали между собой, для этого мы добавим рейтинг топ-20 авторов по количеству статей.
class ArticlesListView(ListView):
# ...
def get_context_data(self, **kwargs):
# ...
context['top_authors'] = list(
Author.objects.order_by('-articles_count'))[:20]
# ...
Здесь мы получаем список всех авторов, отсортированный по количеству статей, и берем первые 20 элементов этого списка.
articles_count, в нашем примере, это денормализованное поле, которое содержит количество статей у данного автора.
На реальном проекте, возможно вы захотели бы настроить сигналы, для актуализации этого поля.
Думаю уже сейчас понятно, что это не самый оптимальный вариант, это подтверждает и DDT:

Конечно нам нужно, чтобы ограничение выборки первыми 20-ю авторами происходило на стороне БД. Для этого нужно понять,
что QuerySet старается максимально отсрочить выполнение запроса к БД. Непосредственно запрос к БД осуществляется в
следующих случаях:
- итерация по QuerySet (например,
for obj in Model.objects.all():), - slicing, если вы используете "нарезку" с определенным шагом (например,
Model.objects.all()[::2]), - применение метода
len(например,len(Model.objects.all()), - применение метода
list(например,list(Model.objects.all()), - применение метода
bool(например,bool(Model.objects.all()), - сериализация при помощи pickle.
Т.е. вызвав list мы заставили QuerySet выполнить запрос к БД и вернуть нам список объектов, после чего уже к нему была
применена операция обрезки. Для того, чтобы ограничение выборки происходило в SQL запросе, нужно применить slicing
к самому QuerySet:
context['top_authors'] = Author.objects.order_by('-articles_count')[:20]
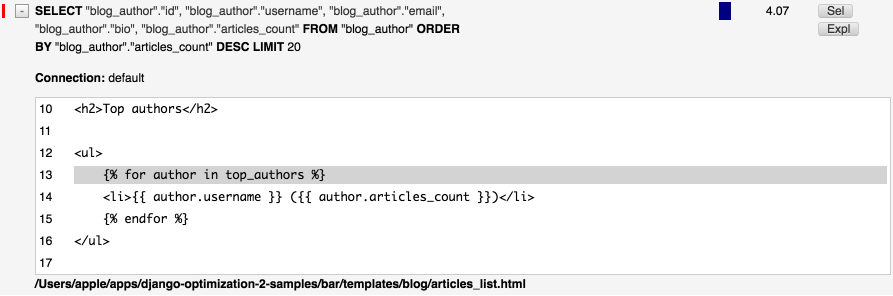
Теперь размер выборки ограничивается в запросе: ...LIMIT 20. Также видно, что отправка запроса
к БД была отложена до итерации по циклу в шаблоне.