Все мы знаем, что node.js так популярен благодаря своей производительности. Он работает быстро благодаря разным факторам, таким как использование движка Google V8 и асинхронному i/o. Именно такая высокая производительность позволяет достаточно долго не задумываться о масштабировании приложения, т.к. даже один запущенный Node.js процесс может обслуживать сотни или даже тысячи запросов в секунду.

Изначально Node.js приложение работает в одном потоке и, соответственно, для обработки запросов используется только одно ядро процессора. Чтобы использовать весь потенциал многоядерных процессоров, необходимо запускать сразу несколько экземпляров приложения, а операционная система позаботится о том, чтобы каждый из них получил вычислительные ресурсы.
Количество потоков лучше всего подбирать опытным путём. Изменяя количество потоков и проводя тестирование производительности. Чаще всего берут количество потоков равное количеству ядер процессора (или количество_ядер + 1).
Сегодня мы рассмотрим:
- каким требованиям должно соответствовать приложение, чтобы успешно масштабироваться
- существующие npm-модули для масштабирования
- сторонние программные решения
Подготовка к масштабированию
Перед тем как приложение будет иметь возможность работать в несколько потоков, нужно решить одну очень важную проблему. А именно, проблему хранения сессий и других, зависимых от клиента, данных в промежутках между запросами.
Когда приложение работает в одном потоке, всё предельно просто. Данные можно хранить в переменных процесса и они будут доступны при каждом запросе. Многие так и поступают в начале разработки и, например, используют массивы для хранения сессионных данных пользователей.
Однако для работы приложения в многопоточном режиме, необходимо убедится в том что каждый процесс может обслужить любой пользовательский запрос. Т.е. все процессы должны быть равноправны и иметь доступ ко всей необходимой информации о пользователях и сессиях.
Одним из простых способов решения данной проблемы является вынесение сессионных данных во внешнее хранилище (например: Memcached, Redis и тд.) и запрос необходимых данных в начале обработки каждого запроса. Эту схему можно изобразить следующим образом:
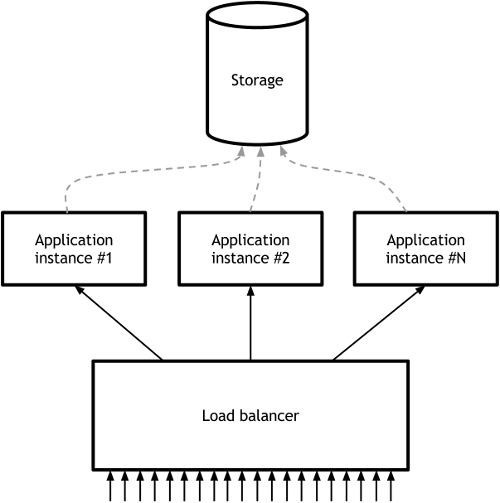
Решения на Node.js
cluster
Cluster - это built-in модуль, позволяющий с лёгкостью запускать несколько процессов, которые делят между собой один порт. В данном случае балансировкой нагрузки занимается операционная система. На момент написания данного поста, модуль является экспериментальным, но мы всё же протестируем его в работе.
В данном случае при запуске приложения необходимо сначала запустить master-процесс, который в свою очередь, запустит необходимое количество дочерних процессов:
var cluster = require('cluster');
cluster.setupMaster({exec: __dirname + '/worker.js'});
for (var i = 0; i < 4; i++) {
cluster.fork();
}
cluster.on('exit', function(worker, code, signal) {
console.log('worker ' + worker.process.pid + ' died');
});
Метод setupMaster принимает параметры в виде объекта. Например, параметр exec задаёт путь к файлу worker'а, который затем будет запускаться на выполнение.
После начальной конфигурации master-север должен запустить необходимое количество рабочих процессов. Для этого используется метод fork.
var cluster = require('cluster');
var http = require('http');
http.createServer(function(req, res) {
res.writeHead(200);
res.end("hello world\n");
}).listen(7000);
console.log("Worker listen on 127.0.0.1:7000");
Создание worker'а мало чем отличается от создания обычного web-сервера. В данном случае мы просто создаём http-сервер и заставляем его слушать 7000 порт.
cluster2
Cluster2 - модуль от сторонних разработчиков, расширяющий возможности стандартного модуля cluster. Модуль добавляет функции, которые позволяют использовать cluster в production окружении. Среди таких функций:
- перезапуск рабочих процессов
- таймаут простоя
- события для логирования
- осторожное завершение процессов и др
Подробнее ознакомится с модулем можно на github.
etc
Ещё несколько модулей:
- clusterhub - an attempt at giving multi process node programs a simple and efficient way to share data
- cluster-master - take advantage of node built-in cluster module behavior
- amino - clustering framework for Node.js
Сторонние программные решения
HAProxy
HAProxy - это специализированное решение для балансировки нагрузок. Содержит огромное количество функций и используется во многих highload проектах. Рассмотрим пример простейшей конфигурации системы на HAProxy.
Для начала необходимо скачать и установить HAProxy, например с официального сайта. После этого нужно создать конфигурационный файл:
global
daemon
maxconn 10000
defaults
mode http
timeout connect 5000ms
timeout client 50000ms
timeout server 50000ms
frontend http-in
bind *:80
default_backend servers
backend servers
balance roundrobin
server server1 127.0.0.1:8000
server server2 127.0.0.1:8001
server server3 127.0.0.1:8002
server server4 127.0.0.1:8003
Если коротко, то данный конфигурационный файл описывает, что HAProxy должен прослушивать 80 порт и перенаправлять каждый запрос на один из серверов, указанны в секции backend. При этом, какой именно сервер получит запрос определяется по алгоритму round-robin.
Node.js приложение необходимо запустить на каждом из указанных портов. При этом какой-то особенной конфигурации приложения не требуется.
HAProxy достаточно сложное решение и больше подходит для очень крупных проектов, где необходимо распределять нагрузку между большим количеством физических серверов или между целыми кластерами.
Nginx
Nginx позволяет описывать группы серверов в конфигурационных файлах и затем балансировать нагрузку между ними при помощи одного из нескольких алгоритмов. Есть возможность задания "веса" сервера, выделение отдельных серверов как резервных и др.
Предположим у нас запущены 8 процессов нашего приложения. Каждый процесс слушает порт, первый процесс - 8000, второй - 8001, и тд. Рассмотрим простой пример конфигурации Nginx для балансировки нагрузки:
upstream backend {
least_conn;
server 127.0.0.1:8000;
server 127.0.0.1:8001;
server 127.0.0.1:8002;
server 127.0.0.1:8003;
server 127.0.0.1:8004;
server 127.0.0.1:8005;
server 127.0.0.1:8006;
server 127.0.0.1:8007;
}
server {
listen 0.0.0.0:80;
location / {
proxy_pass http://backend;
}
}
Теперь Nginx будет принимать запросы на 80 порт и балансировать их между процессами приложения. При этом он будет стараться отдавать запрос тому процессу, который в данный момент меньше всего нагружен.
etc
- Round-robin DNS
- Pound - reverse proxy, load balancer and HTTPS front-end for Web server(s)
- Perlbal - Perl HTTP Load Balancer
Заключение
Какой именно способ выбрать зависит от конкретного случая. Мне кажется, для масштабирования в рамках одного сервера, лучше использовать модуль cluster (или его производные), т.к. это упрощает контроль за запущенными рабочими процессами. В случае если приложение требует вынести на несколько серверов, нужно просто создать несколько таких кластеров и настроить балансировку между ними при помощи Nginx или HAProxy.