Other parts of this guide:
- Part 1. Profiling and Django settings
- Part 2. Working with database
- Part 3. Caching
Table of Contents:
- Mass edit
- Iterator
- Foreign keys
- Retrieving of related objects
- Defer fields retrieving
- Database indexes
- len(qs) vs qs.count
- count vs exists
- Lazy QuerySet
This is the second part of Django project optimization series. The first part was about profiling and Django settings, it's available here. This part will be about working with database optimization (Django models).
We will use SQL logging and Django Debug Toolbar described in the first part of this series. I will use PostgreSQL in all examples, but most part of this guide will be useful for other databases too.
Examples in this part are based on simple blog application, that we will build and optimize throughout the guide. Let's begin with the following models:
from django.db import models
class Tag(models.Model):
name = models.CharField(max_length=64)
def __str__(self):
return self.name
class Author(models.Model):
username = models.CharField(max_length=64)
email = models.EmailField()
bio = models.TextField()
def __str__(self):
return self.username
class Article(models.Model):
title = models.CharField(max_length=64)
content = models.TextField()
created_at = models.DateField()
author = models.ForeignKey(Author)
tags = models.ManyToManyField(Tag)
def __str__(self):
return self.title
All code is available on GitHub with tags.
Mass edit
Mass insertion
Let's imagine, that our new blog application replaces some old one and we need to transfer data to new models. We have exported data from old application to large JSON files. File with authors has following structure:
[
{
"username": "mackchristopher",
"email": "dcortez@yahoo.com",
"bio": "Vitae mollitia in modi suscipit similique. Tempore sunt aliquid porro. Molestias tempora quos corporis quam."
}
]
Let's create Django command to import authors from JSON file:
class Command(BaseCommand):
help = 'Load authors from `data/old_authors.json`'
DATA_FILE_PATH = os.path.join(settings.BASE_DIR, '..', 'data', 'old_data.json')
def handle(self, *args, **kwargs):
with open(self.DATA_FILE_PATH, 'r') as json_file:
data = json.loads(json_file.read())
for author in data:
self._import_author(author)
def _import_author(self, author_data):
author = Author(
username=author_data['username'],
email=author_data['email'],
bio=author_data['bio'])
author.save()
Now we will check how many SQL requests performed on importing 200 authors. Run in python manage.py shell:
from django.core.management import call_command
from django.db import connection
call_command('load_data')
print(len(connection.queries))
This code will print a bunch of SQL requests (because SQL logging is enabled) and in the last line, we will see number 200
This means, that for every author we perform separated INSERT SQL request. If you have huge amount of data, this
approach could be very slow. Let's use method bulk_create of Author model manager:
def handle(self, *args, **kwargs):
with open(self.DATA_FILE_PATH, 'r') as json_file:
data = json.loads(json_file.read())
author_instances = []
for author in data:
author_instances.append(self._import_author(author))
Author.objects.bulk_create(author_instances)
def _import_author(self, author_data):
author = Author(
username=author_data['username'],
email=author_data['email'],
bio=author_data['bio'])
return author
This command generates one huge SQL request for all authors.
If you have really large amount of data, probably, you will need to break insertion into several SQL requests. You can use a
batch_sizeargument of thebulk_createmethod for this. If we want to insert 200 objects (rows) to a database and providebulk_size=50, Django will generate 4 requests.The
bulk_sizemethod has several drawbacks, you can read about them in the documentation.
Mass M2M insertion
Now we need to import articles and tags. They are available in separate JSON file with following structure:
[
{
"created_at": "2016-06-11",
"author": "nichole52",
"tags": [
"ab",
"iure",
"iusto"
],
"title": "...",
"content": "..."
}
]
Let's write another command for this:
class Command(BaseCommand):
help = 'Load articles from `data/old_articles.json`'
DATA_FILE_PATH = os.path.join(settings.BASE_DIR, '..', 'data', 'old_articles.json')
def handle(self, *args, **kwargs):
with open(self.DATA_FILE_PATH, 'r') as json_file:
data = json.loads(json_file.read())
for article in data:
self._import_article(article)
def _import_article(self, article_data):
author = Author.objects.get(username=article_data['author'])
article = Article(
title=article_data['title'],
content=article_data['content'],
created_at=article_data['created_at'],
author=author)
article.save()
for tag in article_data['tags']:
tag_instance, _ = Tag.objects.get_or_create(name=tag)
article.tags.add(tag_instance)
After running this command database received 3349 SQL requests! Most of them look like as follows:
(0.001) SELECT "blog_article_tags"."tag_id" FROM "blog_article_tags" WHERE ("blog_article_tags"."article_id" = 2319 AND "blog_article_tags"."tag_id" IN (67)); args=(2319, 67)
(0.000) INSERT INTO "blog_article_tags" ("article_id", "tag_id") VALUES (2319, 67) RETURNING "blog_article_tags"."id"; args=(2319, 67)
(0.000) SELECT "blog_tag"."id", "blog_tag"."name" FROM "blog_tag" WHERE "blog_tag"."name" = 'fugiat'; args=('fugiat',)
(0.001) SELECT "blog_article_tags"."tag_id" FROM "blog_article_tags" WHERE ("blog_article_tags"."article_id" = 2319 AND "blog_article_tags"."tag_id" IN (68)); args=(2319, 68)
(0.000) INSERT INTO "blog_article_tags" ("article_id", "tag_id") VALUES (2319, 68) RETURNING "blog_article_tags"."id"; args=(2319, 68)
(0.000) SELECT "blog_tag"."id", "blog_tag"."name" FROM "blog_tag" WHERE "blog_tag"."name" = 'repellat'; args=('repellat',)
(0.001) SELECT "blog_article_tags"."tag_id" FROM "blog_article_tags" WHERE ("blog_article_tags"."article_id" = 2319 AND "blog_article_tags"."tag_id" IN (58)); args=(2319, 58)
(0.000) INSERT INTO "blog_article_tags" ("article_id", "tag_id") VALUES (2319, 58) RETURNING "blog_article_tags"."id"; args=(2319, 58
Adding each tag to the article is performed with separated request. We can improve this command by invoking article.tags.add
method with all tags for a current article:
def _import_article(self, article_data):
# ...
tags = []
for tag in article_data['tags']:
tag_instance, _ = Tag.objects.get_or_create(name=tag)
tags.append(tag_instance)
article.tags.add(*tags)
This version sends only 1834 requests, almost 2 times fewer.
Mass update
After data import, we decided, that we need to disallow commenting on old articles (created before 2012). I added
the comments_on boolean field to the Article model. Now, we need to set its values:
from django.db import connection
from blog.models import Article
for article in Article.objects.filter(created_at__year__lt=2012):
article.comments_on = False
article.save()
print(len(connection.queries))
This code generates 179 requests like following:
(0.000) UPDATE "blog_article" SET "title" = 'Saepe eius facere magni et eligendi minima sint.', "content" = '...', "created_at" = '1992-03-01'::date, "author_id" = 730, "comments_on" = false WHERE "blog_article"."id" = 3507; args=('Saepe eius facere magni et eligendi minima sint.', '...', datetime.date(1992, 3, 1), 730, False, 3507)
This code generates an individual request for each article older than 2012. Moreover, this code rewrites all fields of the article. This can overwrite changes made between SELECT and UPDATE requests, that means that we not only get the performance issue, but also we get the race condition.
Instead, we can use update method of QuerySet instance:
Article.objects.filter(created_at__year__lt=2012).update(comments_on=False)
This code generates just one SQL request:
(0.004) UPDATE "blog_article" SET "comments_on" = false WHERE "blog_article"."created_at" < '2012-01-01'::date; args=(False, datetime.date(2012, 1, 1))
If field update requires complex logic, that can't be performed by single UPDATE request, you can compute field values
via Python code and then use one of the following option:
Model.object.filter(id=instance.id).update(field=computed_value)
# or
instance.field = computed_value
instance.save(update_fields=('fields',))
But this options also suffers from race conditions.
Mass delete
Now, we need to remove all articles with tag minus:
from django.db import connection
from blog.models import Article
for article in Article.objects.filter(tags__name='minus'):
article.delete()
print(len(connection.queries))
This code generates 93 requests as follows:
(0.000) DELETE FROM "blog_article_tags" WHERE "blog_article_tags"."article_id" IN (3510); args=(3510,)
(0.000) DELETE FROM "blog_article" WHERE "blog_article"."id" IN (3510); args=(3510,)
At first, this code removes the connection between article and tag. After that, the article itself is deleted. We can perform
this in less amount of requests with delete method of QuerySet instance:
from django.db import connection
from blog.models import Article
Article.objects.filter(tags__name='minus').delete()
print(len(connection.queries))
This code perform the same but only with 3 requests to the database:
(0.004) SELECT "blog_article"."id", "blog_article"."title", "blog_article"."content", "blog_article"."created_at", "blog_article"."author_id", "blog_article"."comments_on" FROM "blog_article" INNER JOIN "blog_article_tags" ON ("blog_article"."id" = "blog_article_tags"."article_id") INNER JOIN "blog_tag" ON ("blog_article_tags"."tag_id" = "blog_tag"."id") WHERE "blog_tag"."name" = 'minus'; args=('minus',)
(0.002) DELETE FROM "blog_article_tags" WHERE "blog_article_tags"."article_id" IN (3713, 3717, 3722, ...); args=(3713, 3717, 3722, ...)
(0.001) DELETE FROM "blog_article" WHERE "blog_article"."id" IN (3713, 3717, ...); args=(3713, 3717, 3722, ...)``sql
At first, ids of all articles, marked with minus tag, are selected. Then the second request removes all connections
between this articles and tags. At last the articles itself are deleted.
Iterator
Let's pretend that we need to export articles to CSV file. This is the command to perform export:
class Command(BaseCommand):
help = 'Export articles to csv'
EXPORT_FILE_PATH = os.path.join(settings.BASE_DIR, '..', 'data', 'articles_export.csv')
COLUMNS = ['title', 'content', 'created_at', 'author', 'comments_on']
def handle(self, *args, **kwargs):
with open(self.EXPORT_FILE_PATH, 'w') as export_file:
articles_writer = csv.writer(export_file, delimiter=';')
articles_writer.writerow(self.COLUMNS)
for article in Article.objects.select_related('author').all():
articles_writer.writerow([getattr(article, column) for column in self.COLUMNS])
For testing purpose, I generated around 100Mb of articles and loaded them to DB. After that, I ran CSV export command with memory profiler.
mprof run python manage.py export_articles
mprof plot
As a result, I received the following graph of memory consumption:
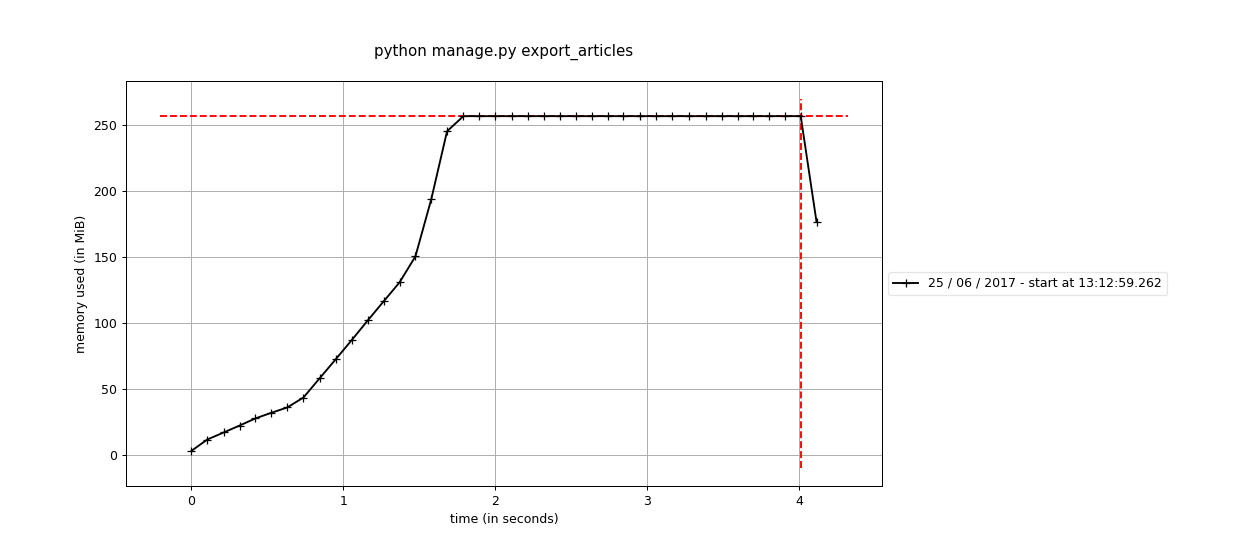
Command utilizes ~250Mb of memory because QuerySet receives all articles from DB at once and caches them to the memory
in order to use it in the next accesses to QuerySet. You can reduce memory consumption through use of iterator method.
This method allows to get query results one by one (with the server-side cursor)
and also it disables caching.
# ...
for article in Article.objects.select_related('author').iterator():
# ...
This is the result of running the updated command in the memory profiler:
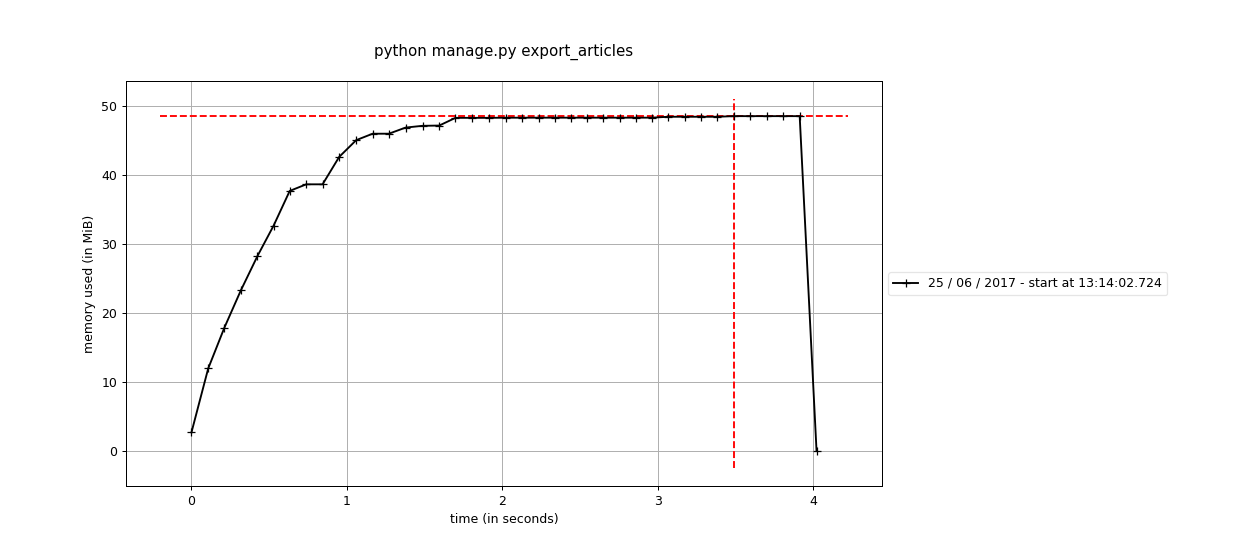
Now the command utilizes only 50Mb of memory. Also, the pleasant side-effect is that memory utilization almost constant
for any amount of articles. Those are results for ~200Mb of articles (without and with the iterator):
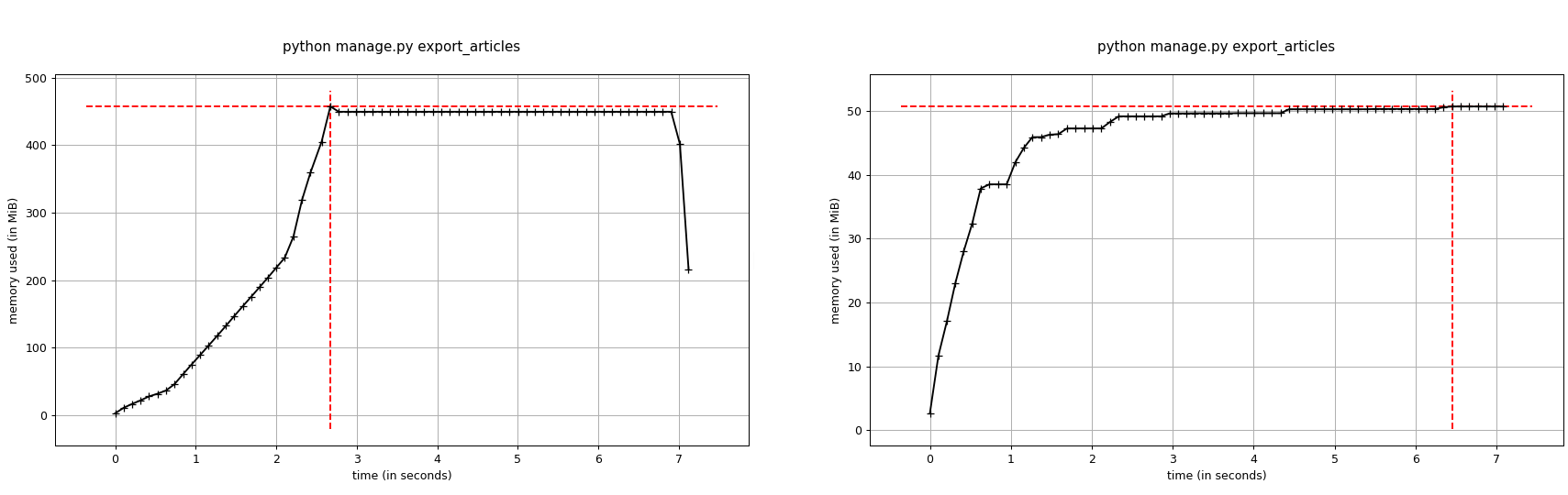
Foreign keys
Now we have to add Django admin action to make a copy of the article:
def clone_article(modeladmin, request, queryset):
if queryset.count() != 1:
modeladmin.message_user(request, "You could clone only one article at a time.", level=messages.ERROR)
return
origin_article = queryset.first()
cloned_article = Article(
title="{} (COPY)".format(origin_article.title),
content=origin_article.content,
created_at=origin_article.created_at,
author=origin_article.author,
comments_on=origin_article.comments_on)
cloned_article.save()
cloned_article.tags = origin_article.tags.all()
modeladmin.message_user(request, "Article successfully cloned", level=messages.SUCCESS)
clone_article.short_description = 'Clone article'
SQL logs:
(0.001) SELECT COUNT(*) AS "__count" FROM "blog_article" WHERE "blog_article"."id" IN (31582); args=(31582,)
(0.001) SELECT "blog_article"."id", "blog_article"."title", "blog_article"."content", "blog_article"."created_at", "blog_article"."author_id", "blog_article"."comments_on" FROM "blog_article" WHERE "blog_article"."id" IN (31582) ORDER BY "blog_article"."created_at" DESC, "blog_article"."id" DESC LIMIT 1; args=(31582,)
(0.000) SELECT "blog_author"."id", "blog_author"."username", "blog_author"."email", "blog_author"."bio" FROM "blog_author" WHERE "blog_author"."id" = 2156; args=(2156,)
(0.001) INSERT INTO "blog_article" ("title", "content", "created_at", "author_id", "comments_on") VALUES ('Explicabo maiores nobis cum vel fugit. (COPY)', ...
For some reason, author's data is also fetched from DB, but we don't need any information about author besides his/her id
(that already is in the article as a foreign key). To fix this you need to refer directly to a foreign key through
origin_article.author_id. I rewrote cloned object population as follows:
cloned_article = Article(
title="{} (COPY)".format(origin_article.title),
content=origin_article.content,
created_at=origin_article.created_at,
author_id=origin_article.author_id,
comments_on=origin_article.comments_on)
And there is no author related request in logs.
Retrieving of related objects
It's time to make our articles public. I will begin with simple articles list page. Let's build view:
class ArticlesListView(ListView):
template_name = 'blog/articles_list.html'
model = Article
context_object_name = 'articles'
paginate_by = 20
There is information about an article, author and tags in the template:
<article>
<h2>{{ article.title }}</h2>
<time>{{ article.created_at }}</time>
<p>Author: {{ article.author.username }}</p>
<p>Tags:
{% for tag in article.tags.all %}
{{ tag }}{% if not forloop.last %}, {% endif %}
{% endfor %}
</article>
DDT shows us that this page generates 45 SQL request as follows:
(0.002) SELECT "blog_article"."id", "blog_article"."title", "blog_article"."content", "blog_article"."created_at", "blog_article"."author_id", "blog_article"."comments_on" FROM "blog_article" LIMIT 20; args=()
(0.001) SELECT "blog_author"."id", "blog_author"."username", "blog_author"."email", "blog_author"."bio" FROM "blog_author" WHERE "blog_author"."id" = 2043; args=(2043,)
(0.001) SELECT "blog_tag"."id", "blog_tag"."name" FROM "blog_tag" INNER JOIN "blog_article_tags" ON ("blog_tag"."id" = "blog_article_tags"."tag_id") WHERE "blog_article_tags"."article_id" = 20425; args=(20425,)
(0.000) SELECT "blog_author"."id", "blog_author"."username", "blog_author"."email", "blog_author"."bio" FROM "blog_author" WHERE "blog_author"."id" = 2043; args=(2043,)
(0.001) SELECT "blog_tag"."id", "blog_tag"."name" FROM "blog_tag" INNER JOIN "blog_article_tags" ON ("blog_tag"."id" = "blog_article_tags"."tag_id") WHERE "blog_article_tags"."article_id" = 20426; args=(20426,)
Primarily we receive all articles (with considering of pagination). Then authors and tags are obtained for each article apart. Our goal is to make Django get all this related data in minimum possible amount of database requests.
Let's begin with authors. To make QuerySet retrieve related data by foreign keys we need to use the select_related method. I updated the queryset in view as follows:
queryset = Article.objects.select_related('author')
After that DDT shows us that the amount of SQL requests is reduced to 25. That happens because data about articles and
authors data is fetched now by a single JOIN SQL request:
(0.004) SELECT "blog_article"."id", "blog_article"."title", "blog_article"."content", "blog_article"."created_at", "blog_article"."author_id", "blog_article"."comments_on", "blog_author"."id", "blog_author"."username", "blog_author"."email", "blog_author"."bio" FROM "blog_article" INNER JOIN "blog_author" ON ("blog_article"."author_id" = "blog_author"."id") LIMIT 21; args=()
The select_realted method works only with foreign keys in the current model. To reduce an amount of requests while fetching
multiple related objects (like tags in our example), we need to use the prefetch_related method. The updated queryset
looks like this:
queryset = Article.objects.select_related('author').prefetch_related('tags')
Now DDT shows only 7 requests. Only 2 of them are responsible for displaying articles list:
(0.002) SELECT "blog_article"."id", "blog_article"."title", "blog_article"."content", "blog_article"."created_at", "blog_article"."author_id", "blog_article"."comments_on", "blog_author"."id", "blog_author"."username", "blog_author"."email", "blog_author"."bio" FROM "blog_article" INNER JOIN "blog_author" ON ("blog_article"."author_id" = "blog_author"."id") LIMIT 20; args=()
(0.001) SELECT ("blog_article_tags"."article_id") AS "_prefetch_related_val_article_id", "blog_tag"."id", "blog_tag"."name" FROM "blog_tag" INNER JOIN "blog_article_tags" ON ("blog_tag"."id" = "blog_article_tags"."tag_id") WHERE "blog_article_tags"."article_id" IN (16352, 16353, 16354, 16355, 16356, 16357, 16358, 16359, 16360, 16361, 16362, 16363, 16344, 16345, 16346, 16347, 16348, 16349, 16350, 16351); args=(16352, 16353, 16354, 16355, 16356, 16357, 16358, 16359, 16360, 16361, 16362, 16363, 16344, 16345, 16346, 16347, 16348, 16349, 16350, 16351)
You must use
select_relatedto retrieve objects by a foreign key in the current model. To retrieve M2M objects and objects from other models that refer to the current one you should useprefetch_related.Also, you can use
prefetch_relatedto fetch related objects of arbitrary nesting levels.
Tag.objects.all().prefetch_related('article_set__author')This code will fetch all articles and corresponding authors with tag.
Defer fields retrieving
If you look closer to the previous example you can see that we retrieve more fields than we needed. This is the result of the request in DDT:
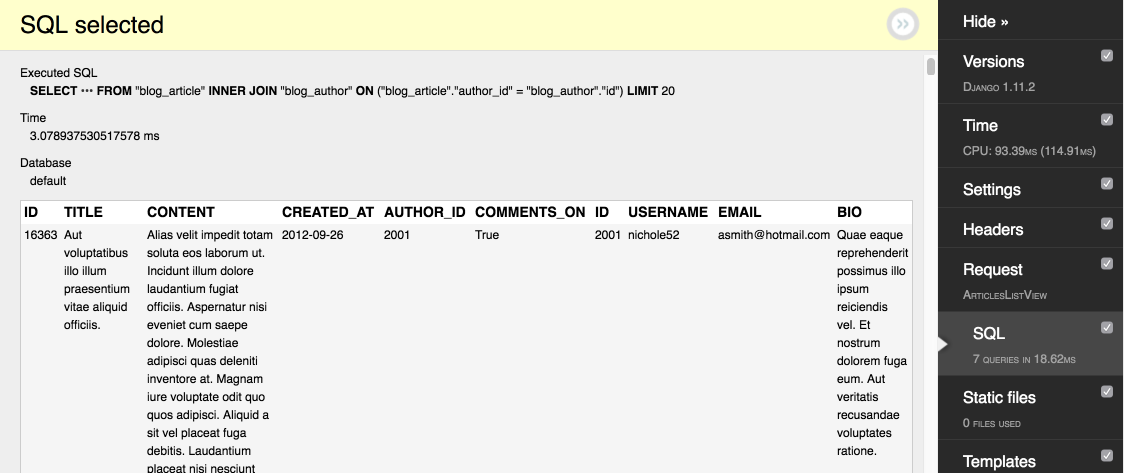
This SQL request retrieves all fields of article and author, including a potentially huge text of an article. You can
significantly reduce an amount of transferring data with defer method. This method defers retrieving of given fields.
In case of some code tries to access deferred field it will be retrieved in separate SQL request on-demand. Let's add
defer invocation to the queryset:
queryset = Article.objects.select_related('author').prefetch_related('tags').defer('content', 'comments_on')
Now Django don't retrieve unneeded fields and this reduces the time of request processing (before and after defer):

But this request still fetches more data than we need. We receive all author fields. It would be easier to give a list of fields that we actually need. We can use 'only' method to define required fields, other fields will be deferred:
queryset = Article.objects.select_related('author').prefetch_related('tags').only(
'title', 'created_at', 'author__username', 'tags__name')
As a result, we receive only data we need:
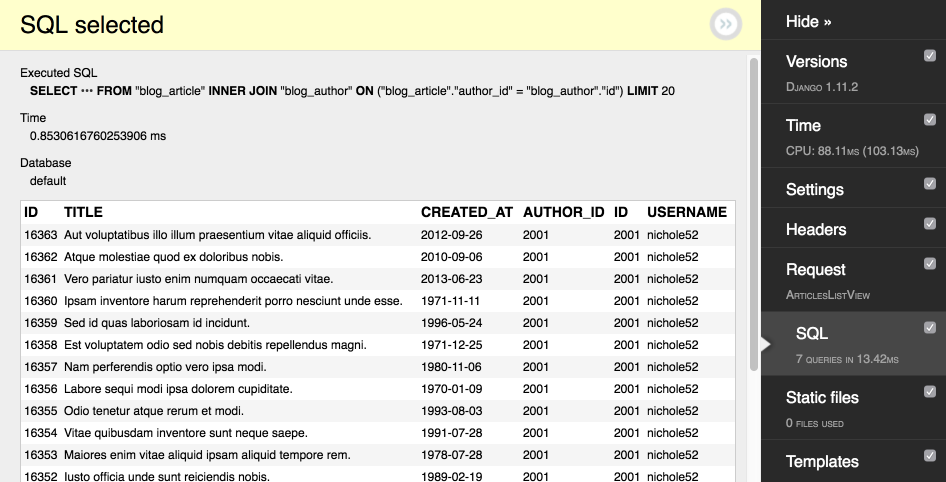
defer and only perform the same task - limiting fetched fields in requests. Differences between this methods are:
deferdefers only specified fields,onlydefers all fields except specified.
Database indexes
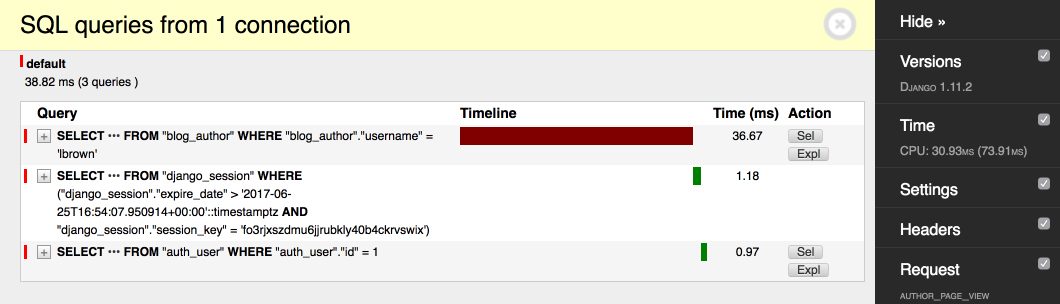
Now we decided to create an author page, that should be accessible by URL like this: /authors/<username>.
def author_page_view(request, username):
author = get_object_or_404(Author, username=username)
return render(request, 'blog/author.html', context=dict(author=author))
This code works pretty fast on a small amount of data. But if an amount of data is big and continues to grow, performance
inevitably falls. That's because DBMS has to scan the entire table to find a row by username field. A better
approach is to use database indexes. They allow DBMS to search data much faster. For adding an index to the field you should
add the db_index=True argument to the corresponding model field. After that, you should make and execute the migration.
class Author(models.Model):
username = models.CharField(max_length=64, db_index=True)
# ...
Let's compare the performance before and after we added the index on a database that contains 100K of authors:
Without index:
With index:
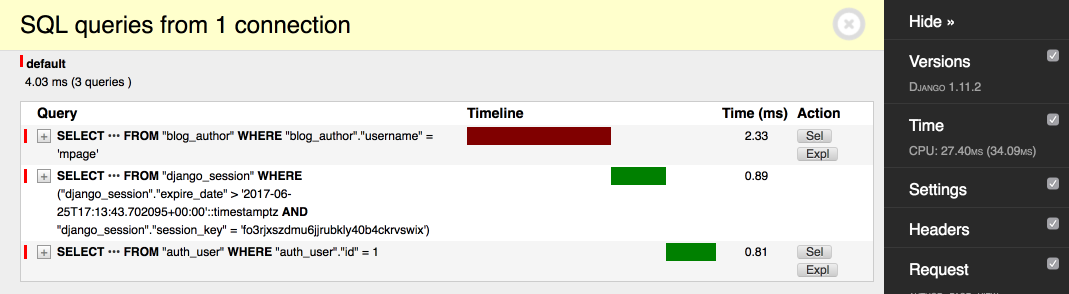
The request is 16x times faster now!
Indexes are useful not only for data filtration. They speed up sortation as well. Also, many of DBMS provide multi-field indexes to speed up filtration and sorting by several fields. You should read a documentation to your DBMS for details.
len(qs) vs qs.count
For some reason, we decided to display a counter of authors on the articles list page. Let's update the view:
class ArticlesListView(ListView):
# ...
def get_context_data(self, **kwargs):
context = super().get_context_data(**kwargs)
context['authors_count'] = len(Author.objects.all())
return context
This code generates following SQL request:

On the screenshot, you can see that we fetch all authors from a database. Therefore counting is performed by the Python
code in view. The optimal approach is to retrieve only the number of authors from the database. We can use count
method for this:
context['authors_count'] = Author.objects.count()
This is a request generated by the updated code:

Now Django generates a much more optimal request for our task.
count vs exists
We need to display a link to author's articles on the author's page, but only if he has any. One possible solution is to retrieve a count of articles and compare it if it is more than 0. Like this:
def author_page_view(request, username):
author = get_object_or_404(Author, username=username)
show_articles_link = (author.articles.count() > 0)
return render(
request, 'blog/author.html',
context=dict(author=author, show_articles_link=show_articles_link))
But if we have a huge amount of articles this code will work slowly. Since we don't need to know the exact amount of articles,
we could use exists method, that checks if QuerySet has at least one result.
# ...
show_articles_link = author.articles.exists()
# ...
Let's compare performance on a large amount of articles (~10K):

So, we reach the goal with requests that 10x faster.
Lazy QuerySet
Now we want the authors to compete each over. For that we will add a rating of top-20 authors by articles count.
class ArticlesListView(ListView):
# ...
def get_context_data(self, **kwargs):
# ...
context['top_authors'] = list(
Author.objects.order_by('-articles_count'))[:20]
# ...
Here we retrieve the list of all authors sorted by articles count and slice first 20 from it. articles count in this
example is a denormalized field with a count of articles of the current user. In a real project, you would probably want
to add signals to update this field on data changes.
I think it's clear that this approach is not ideal. DDT confirms this:

Of course, we need to receive already truncated list of authors from the database. For that you need to understand that
QuerySet tries to defer hitting the database as far as possible. QuerySet hits database in the following cases:
- iteration (i.e.,
for obj in Model.objects.all():), - slicing with specified step (i.e.,
Model.objects.all()[::2]), - call of
len(i.e.,len(Model.objects.all()), - call of
list(i.e.,list(Model.objects.all()), - call of
bool(i.e.,bool(Model.objects.all()), - serialization with pickle.
Therefore by calling list we forced QuerySet to hit database and return a list of objects. Slicing was performed
on the list, not on QuerySet. To limit authors in a SQL request we should apply slicing to QuerySet itself:
context['top_authors'] = Author.objects.order_by('-articles_count')[:20]
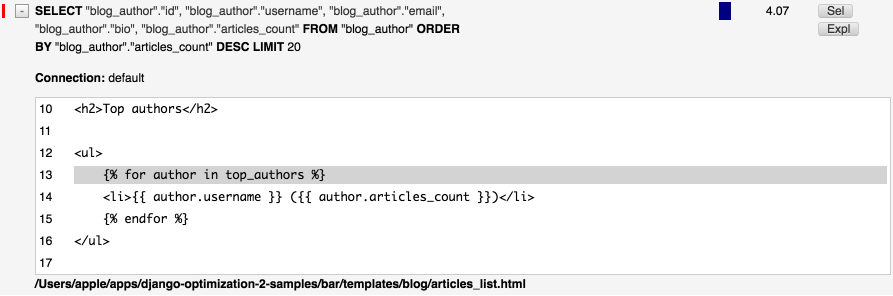
As you can see, a size of a fetch is limited in the request: ...LIMIT 20. Also, DDT shows that QuerySet deferred
hitting the DB until template rendering.